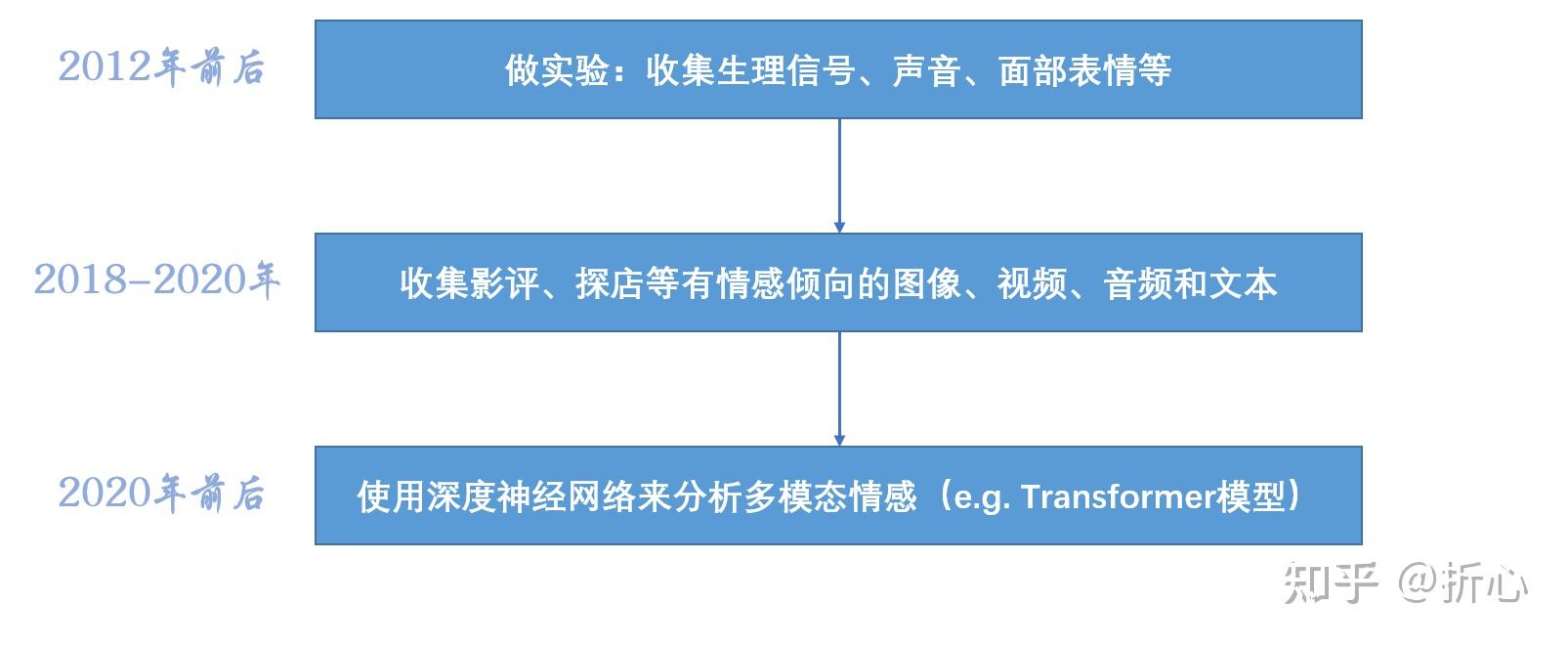
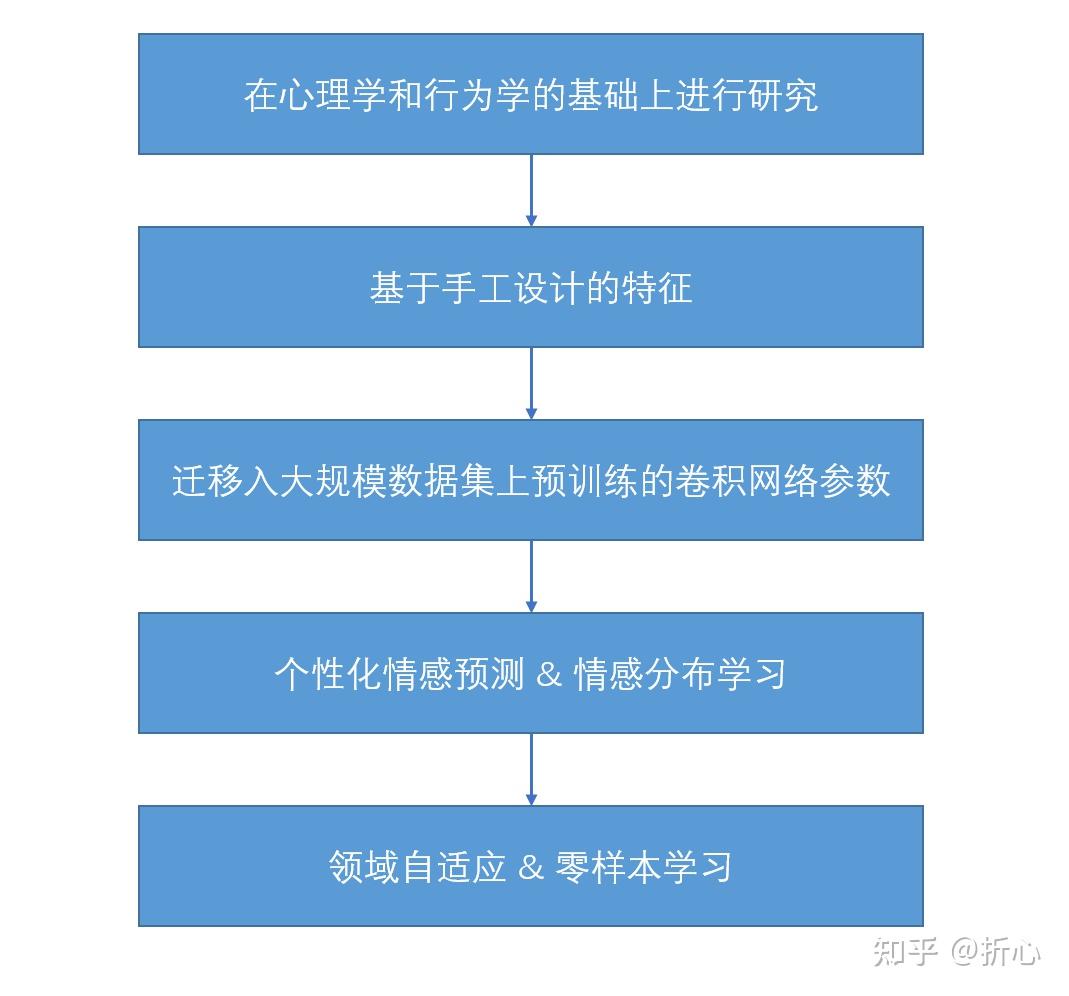
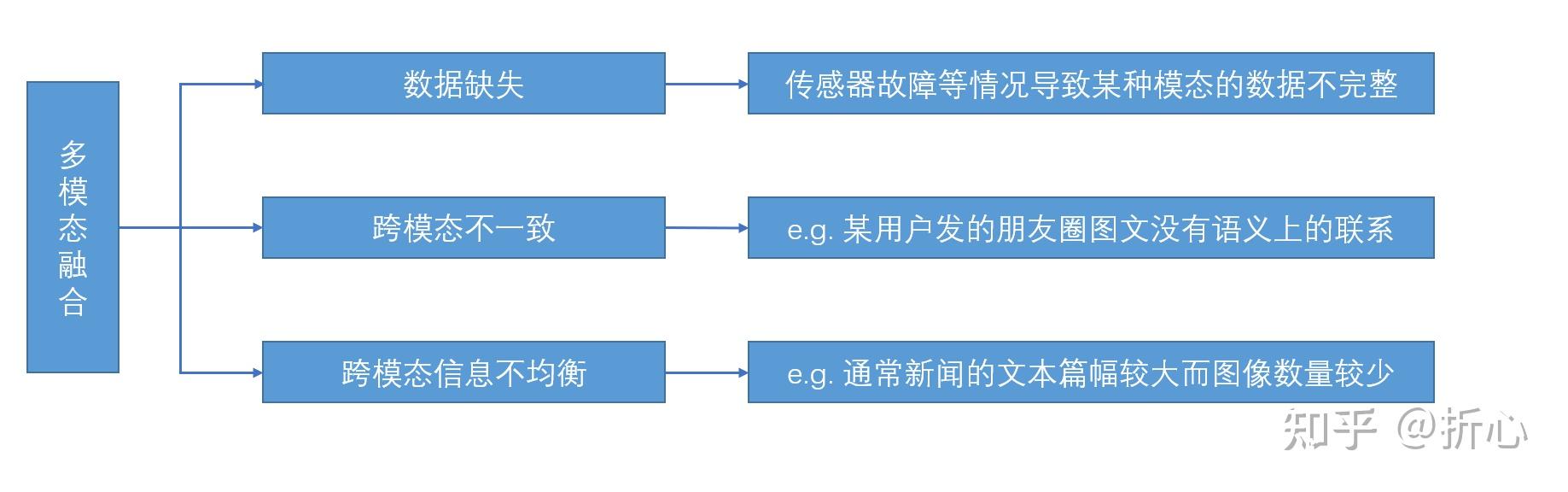
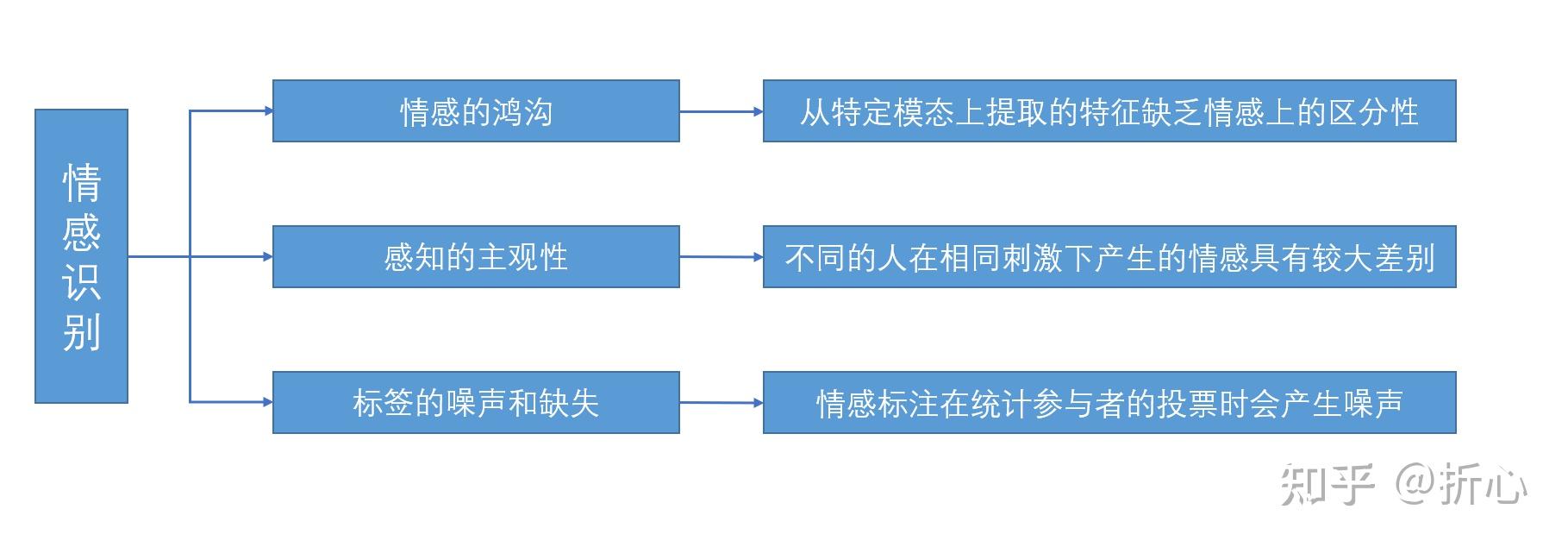
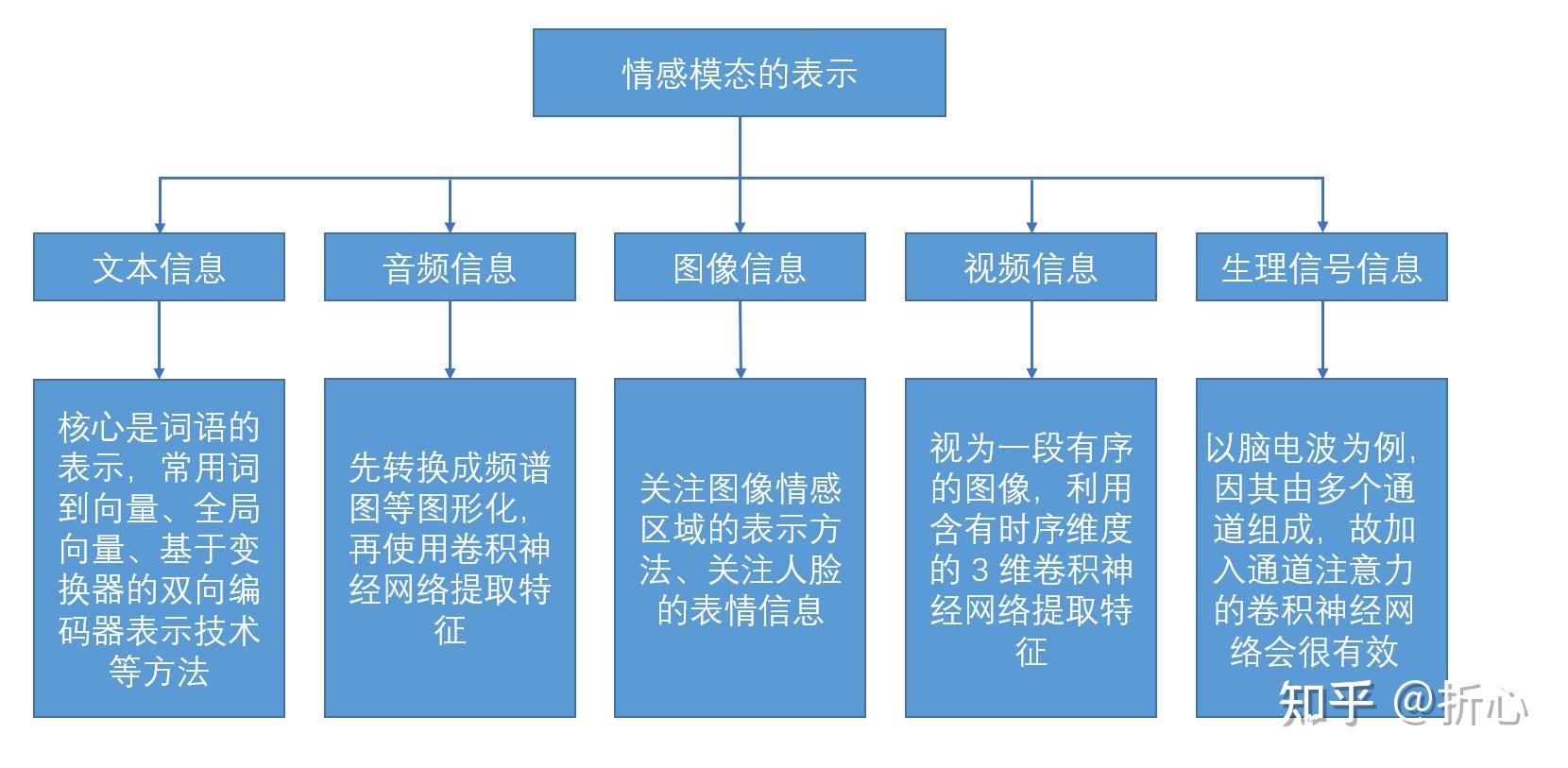
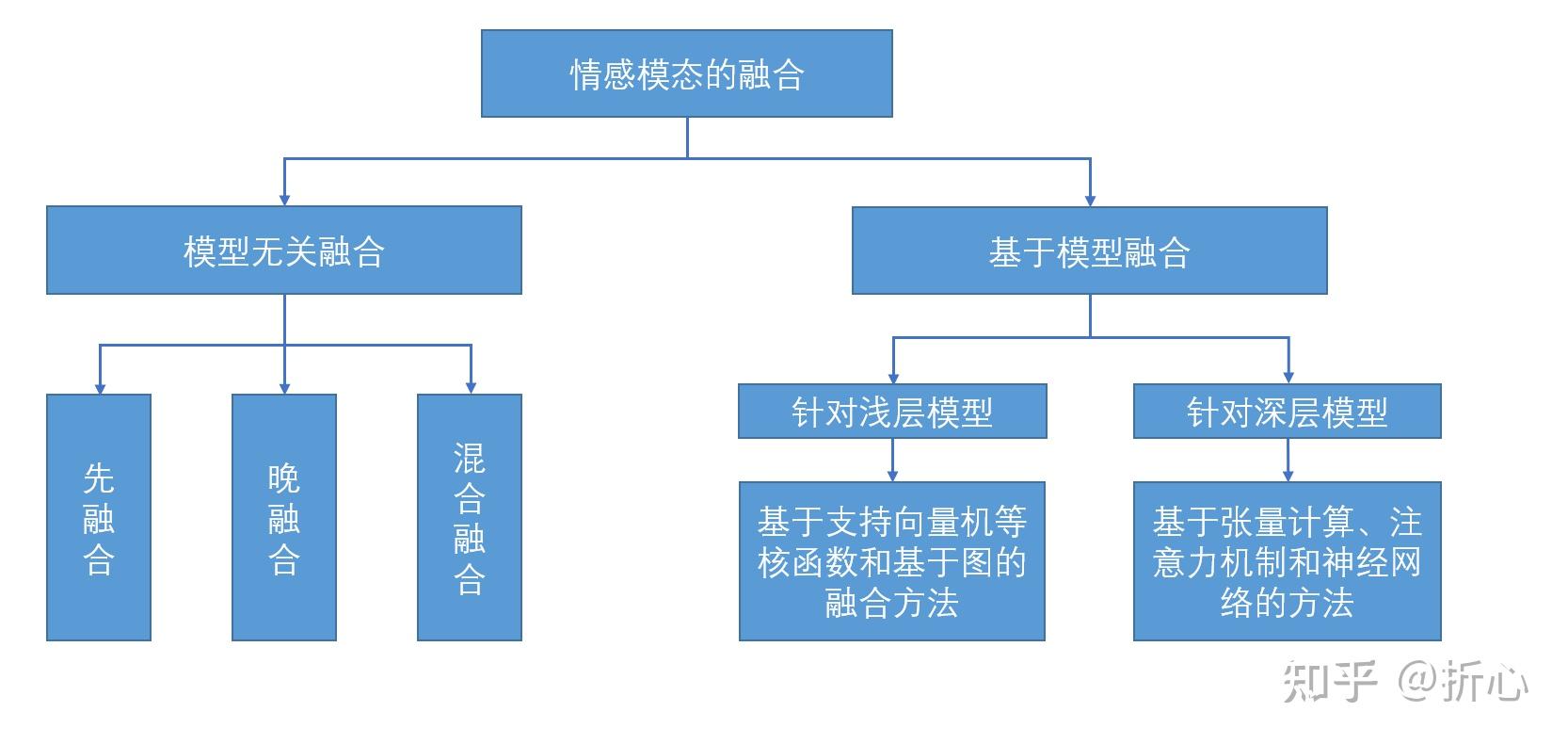
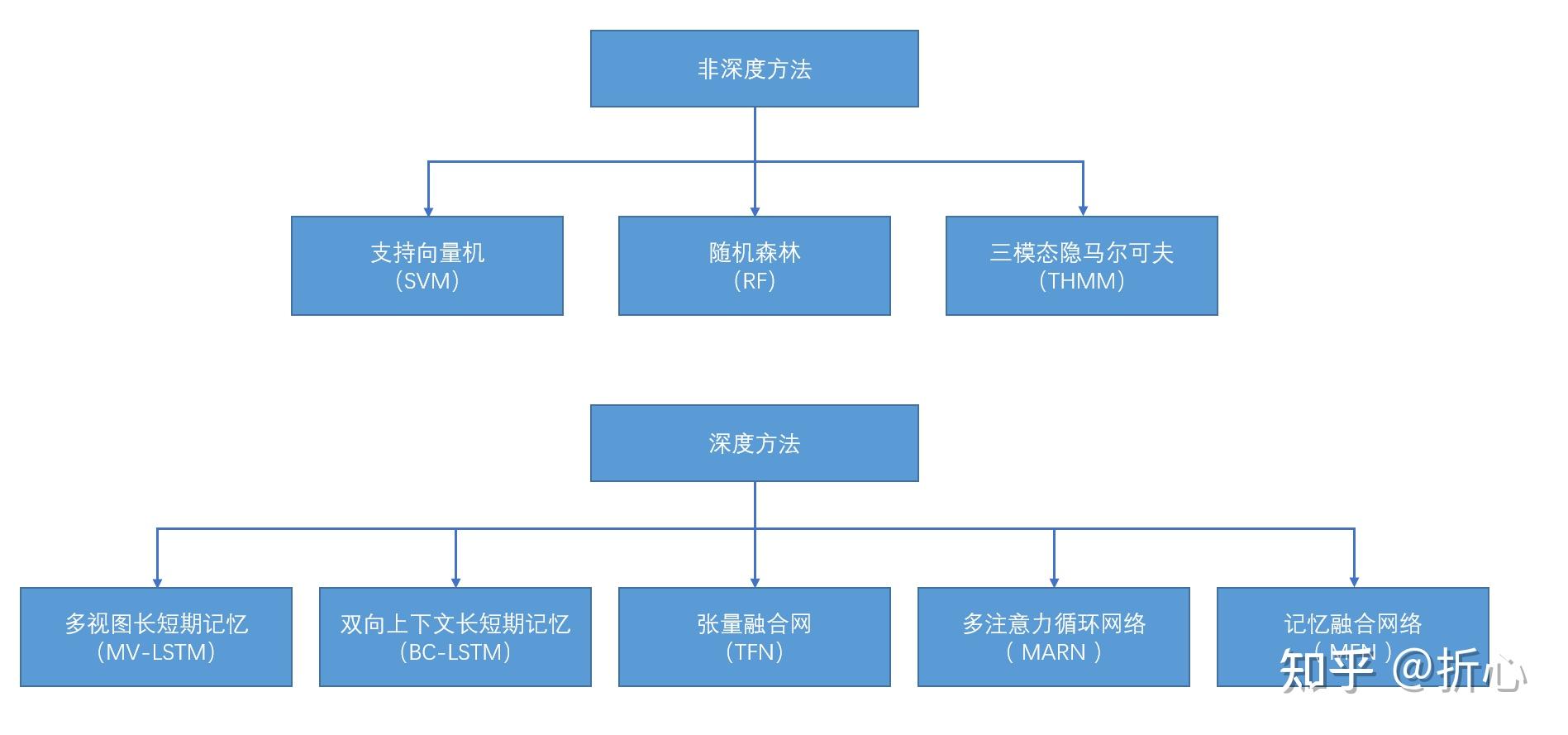
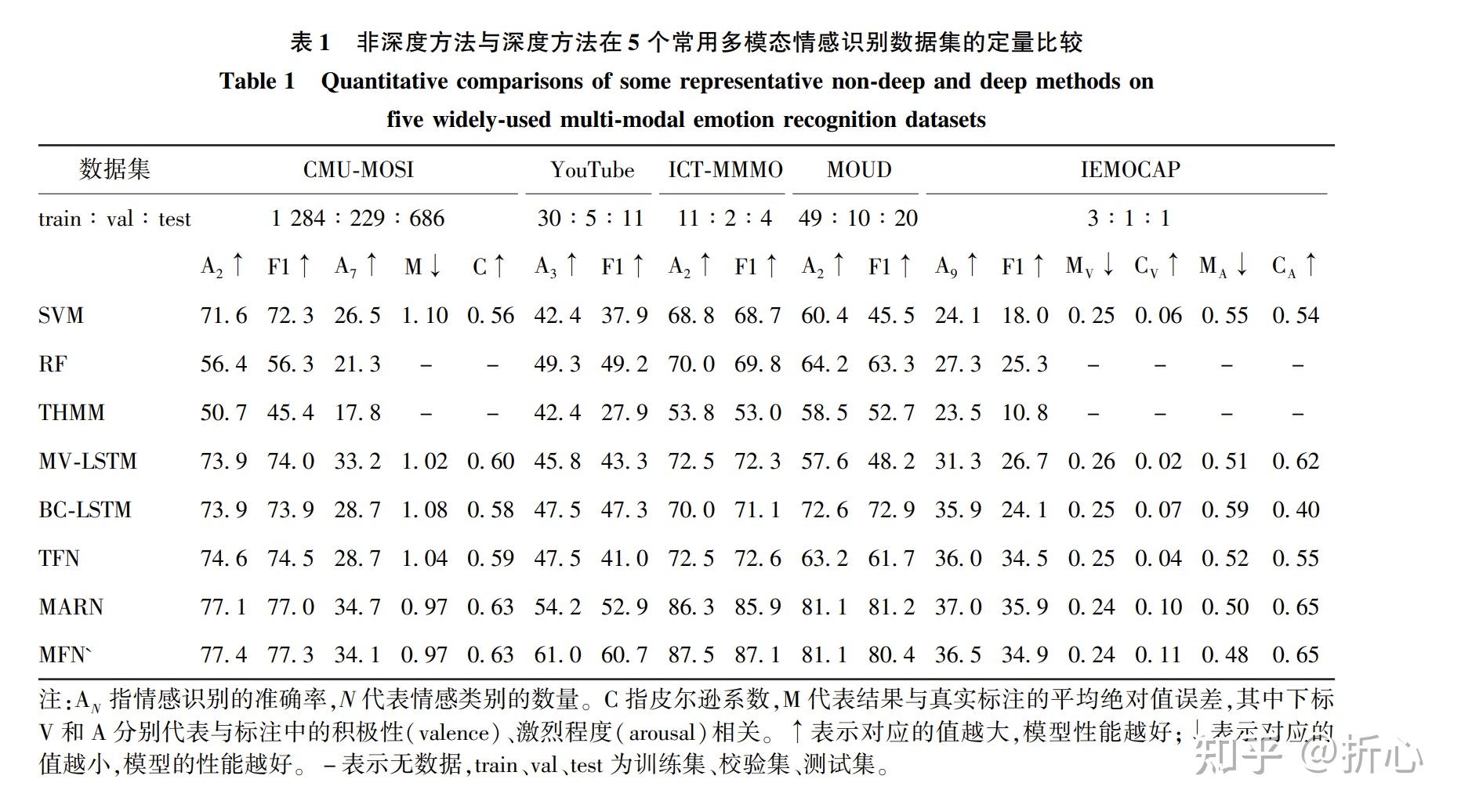
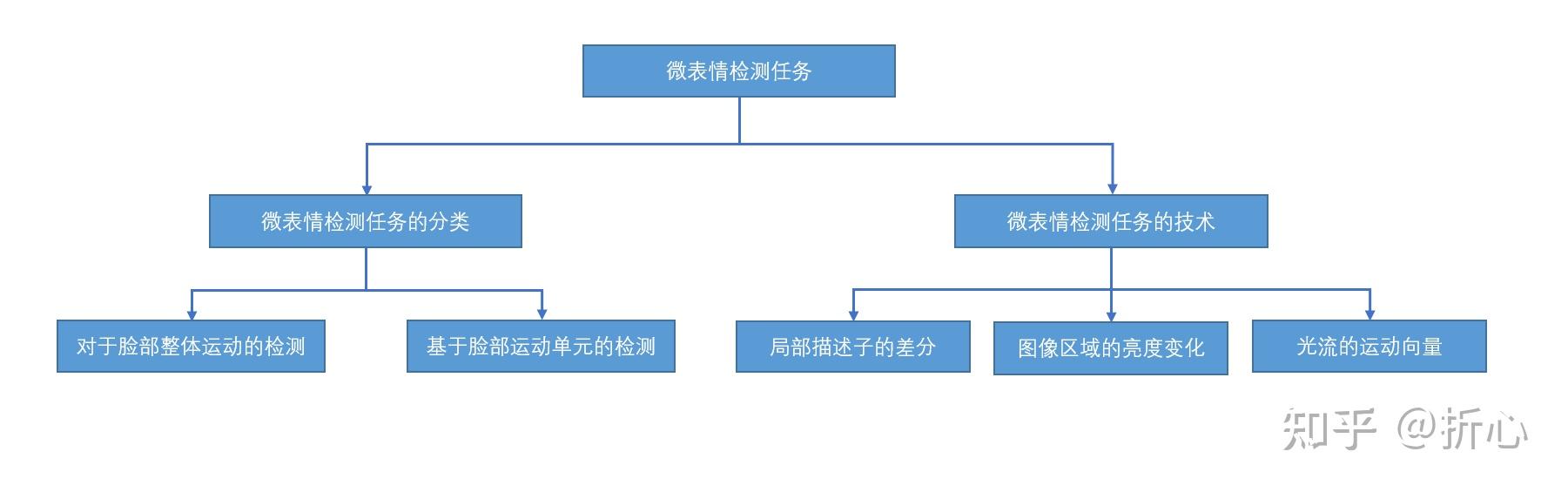
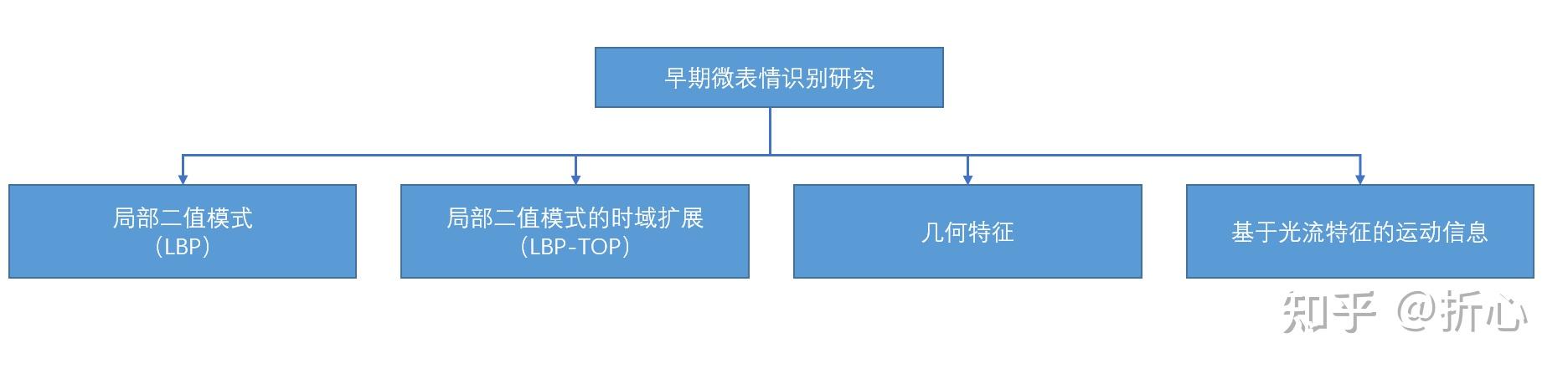
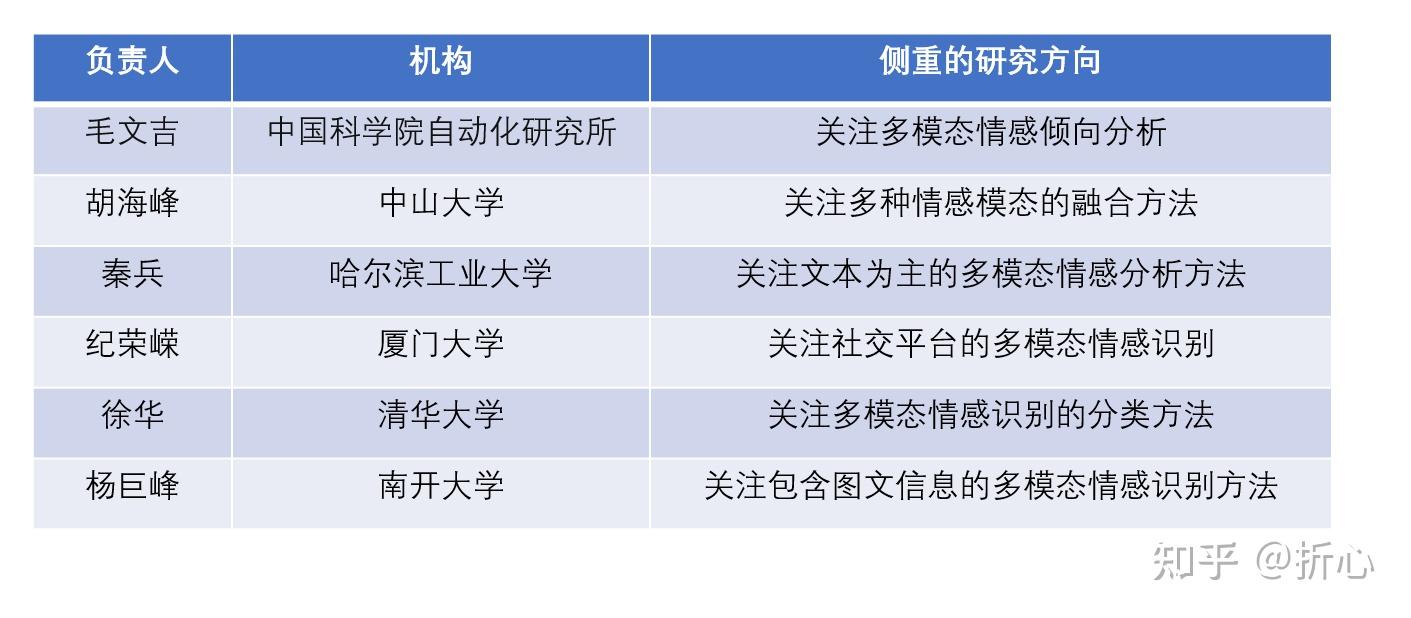
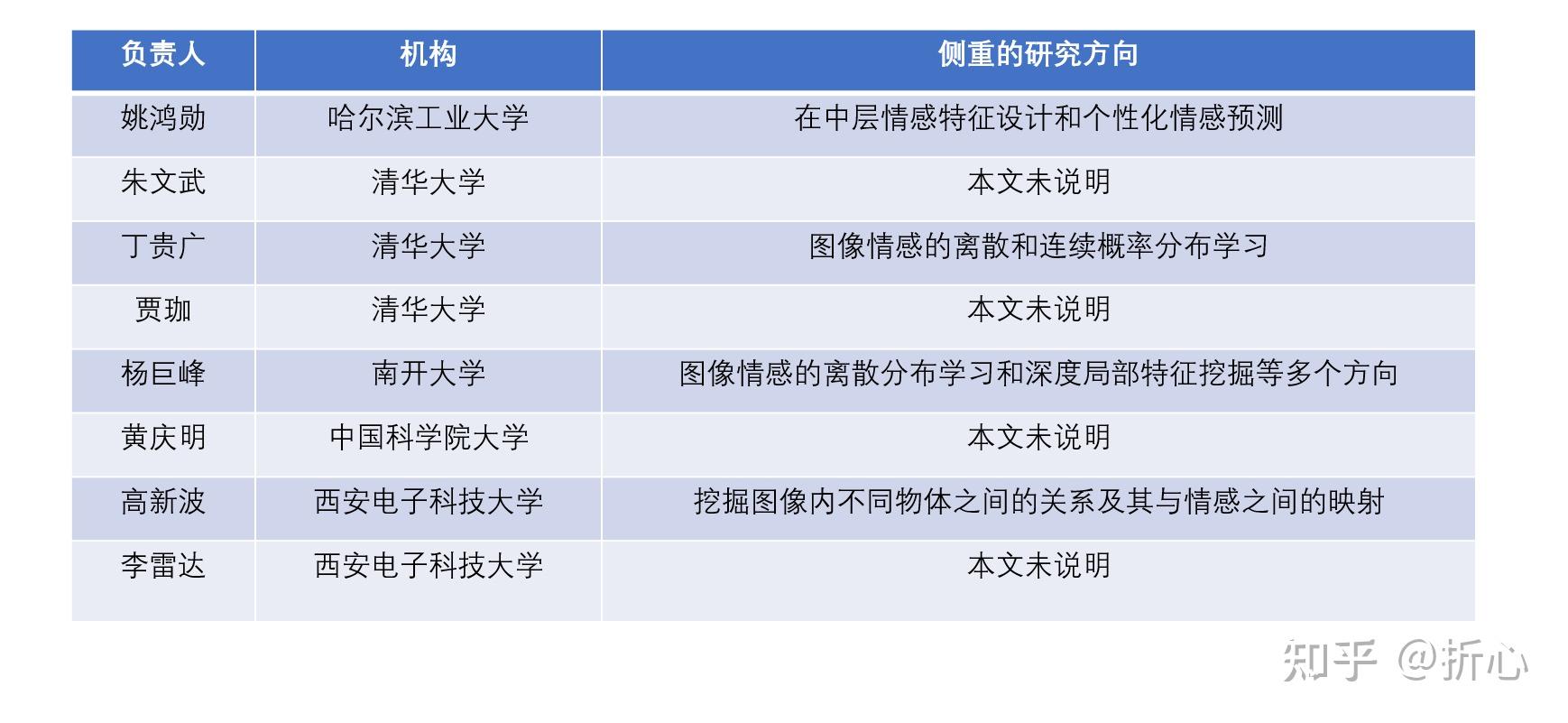
这里说明一下“基于手工设计的特征”的含义(参考某CSDN文章:http://t.csdn.cn/meveN)。
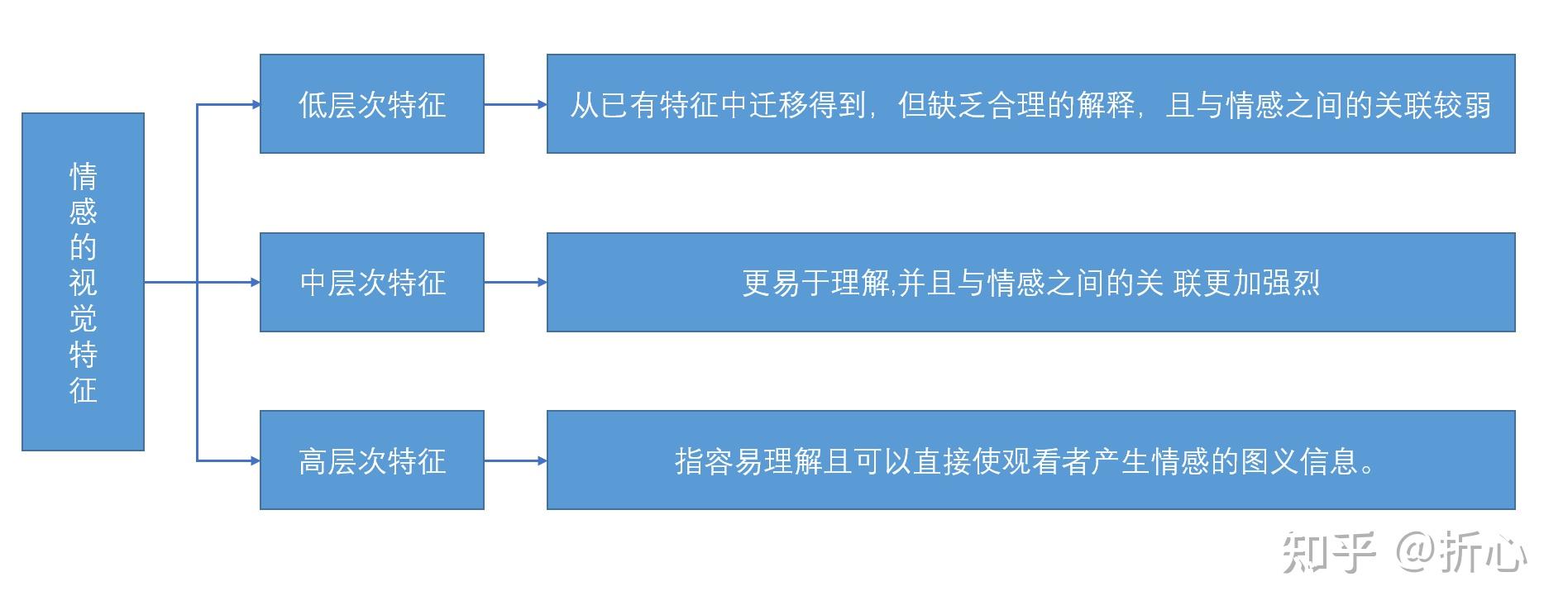
传统的手工特征大致有两类:底层特征和中层特征。其中,底层特征包括颜色、纹理、形状、梯度等基于图像自身的、较为简单的特征;而中层特征一般指在底层特征基础上进行多特征融合处理获得的特征。随着神经网络的快速发展,又出现了深层次的特征,即通过神经网络模型挖掘出的更深层、更抽象的图像特征。
在作者举到的几个例子中,底层特征有全局Wiccest和Gabor特征、艺术元素,中层特征有艺术原理,深层特征(原文是高层次)有形容词名词对。
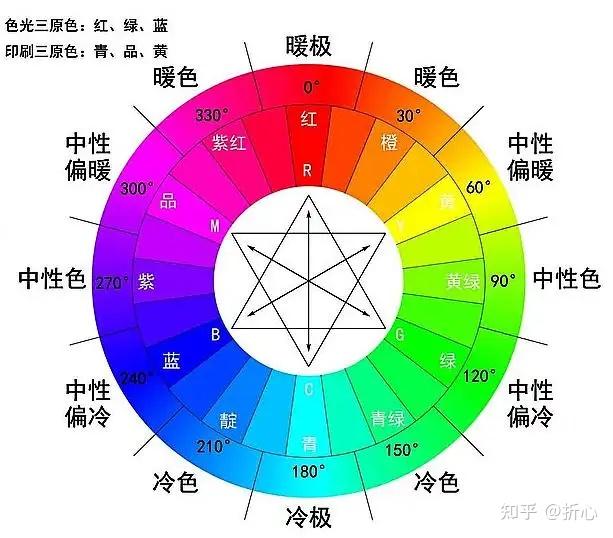
借用Emotional Valence Categorization Using Holistic Image Features这篇论文(Yanulevskaya等人的研究,本篇综述中也有提到他们)里的介绍,Wiccest和Gabor特征都是对图像纹理结构提取出来的特征。原句如下,因为不是重点,就不翻译了。
Wiccest features utilize natural image statistics to effectively model texture information.
Gabor filters may be used to measure perceptual surface texture in an image.
Li 等人(2015,2018)对LBP、HIGO(Histograms of Image Gradient Orientation)和HOG(Histograms of Oriented Gradients)的时空变种进行对比,发现只体现梯度方向信息而不反映梯度能量信息的HIGO-TOP描述子在微表情分析上相比LBP-TOP和HOG-TOP更为高效。在此基础上构建了第1个完整的微表情检测与识别的系统,并进行了人机对战实验。



 发表于 2022-11-30 09:51:40
发表于 2022-11-30 09:51:40