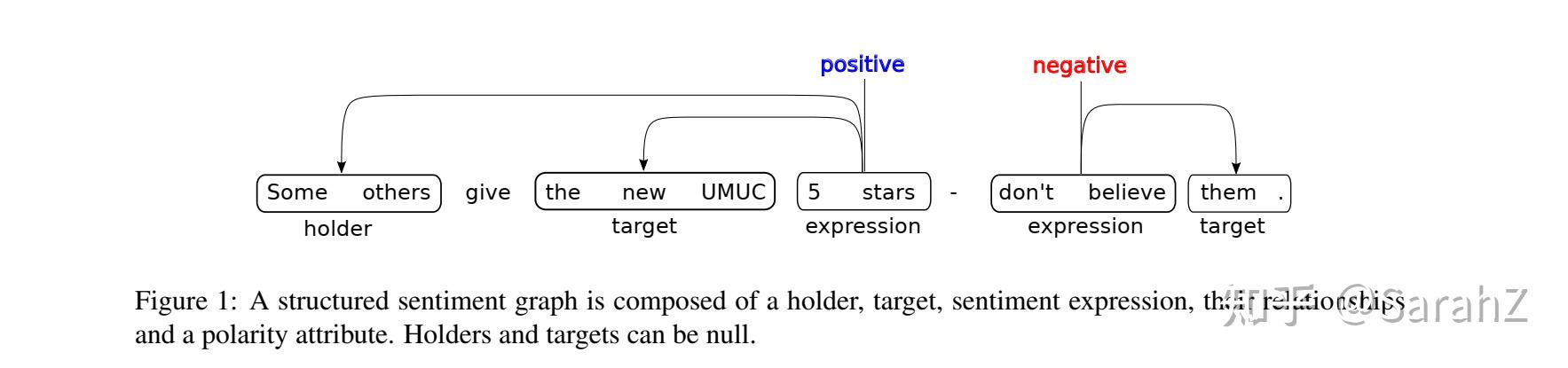
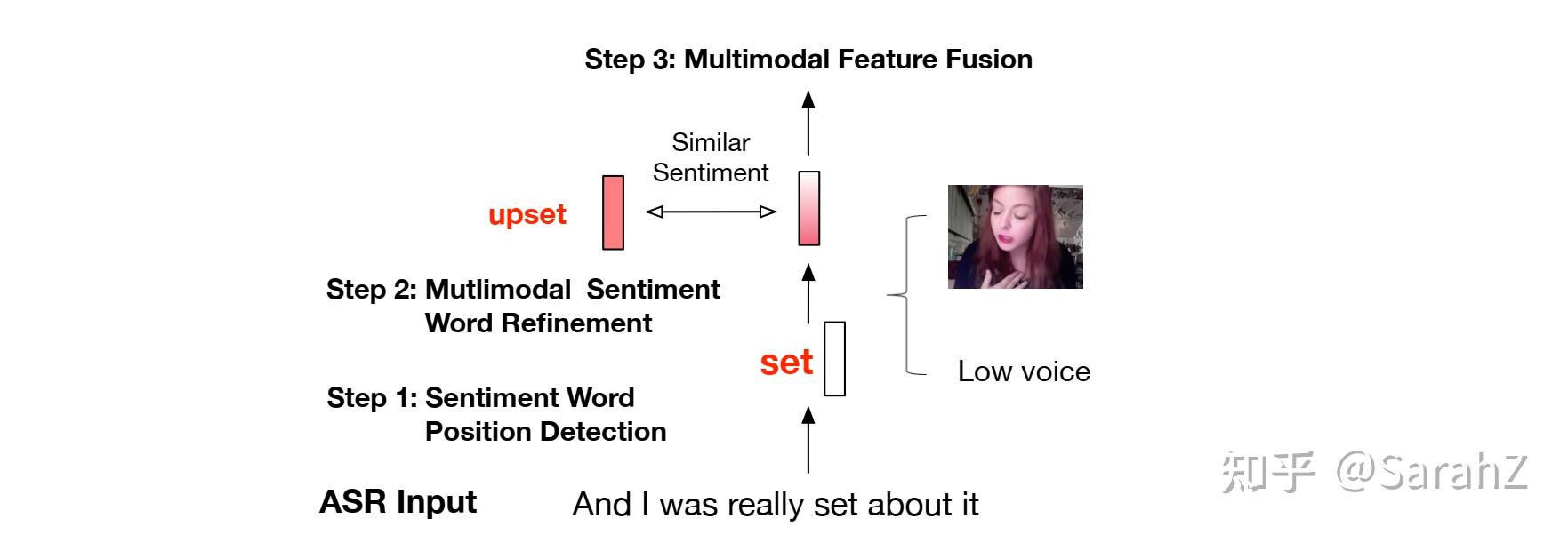
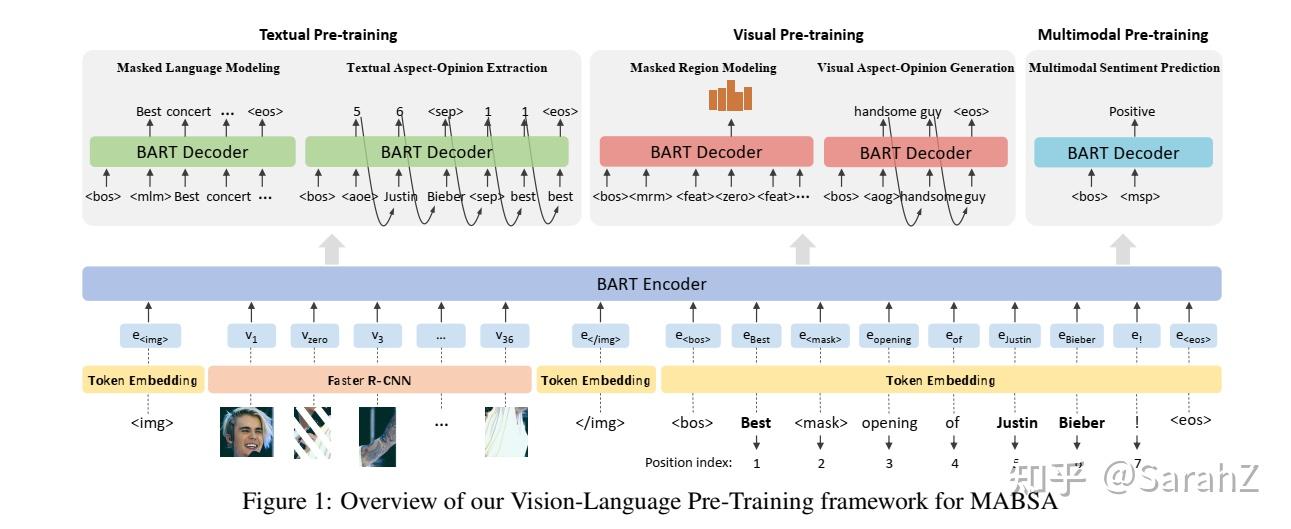
方面术语抽取(ATE)和方面情感分类(ASC)是方面级情感分析(ALSA)中两个基础的细粒度子任务。在文本分析中,联合提取方面术语和情感极性比单独的子任务具有更好的实用性((Wan et al., 2020;Chen and Qian, 2020b; Ying et al., 2020)),因此受到了广泛关注。然而,在多模态场景下,现有研究局限于独立处理每个子任务,未能建模上述两个目标之间的固有联系,并忽略了更好的应用。
提出
广泛的实验表明,该方法对联合文本方法、管道和坍缩多模态方法的有效性。
25 Improving Multimodal Fusion with Hierarchical Mutual Information Maximization for Multimodal Sentiment Analysis(2021EMNLP)



 发表于 2022-12-5 14:35:47
发表于 2022-12-5 14:35:47